


In the past couple of weeks of our Focus Issue on Digital Botany, we have seen the scale of the work being done by herbaria around the world to digitise their collections and make them available online. Millions of specimens — including around 7.3 million at the Royal Botanic Gardens, Kew, and 4.6 million at the New York Botanical Garden — are becoming available to researchers, students and plant enthusiasts far beyond the walls of their institutions. But access is only the first step.
Once these collections are online, users still need ways to search, interpret and identify specimens at scale. Researchers are developing tools to help — so that exploring millions of specimens becomes more than simply clicking through them one by one. Here are three useful tools and workflows that deserve a place in every digital botanist’s toolkit.
Wikidata: connecting scattered pieces of botanical knowledge
Wikidata, Wikipedia’s sister project, is a multilingual, open knowledge base that helps connect pieces of botanical information that are often kept apart. What kind of information? Pretty much everything: a plant species, a collector, a publication, a field expedition, a collection site or even a DNA sequence. Each of these can have its own Wikidata item, with a unique identifier that can be linked to others, creating a connected network of botanical knowledge.
For botanists, the real value of Wikidata lies in what those links make possible. A useful example is the story of Oxalis psoraleoides subsp. insipida, which Sabine von Mering and colleagues present in their recent paper. Through Wikidata, a user can follow this plant across more than two centuries of botanical work: from Saint-Hilaire’s collections in Brazil, to Darwin’s Oxalis specimen from Fernando de Noronha, to Alicia Lourteig’s later taxonomic revision. Wikidata can then extend the trail to older collections, name-bearing publications, molecular studies, DNA sequences, flower visitors and traditional uses. In other words, Wikidata can turn separate facts or links that researchers would otherwise have to piece together manually into a connected history of a plant, its names, its collectors and its uses. Users can explore these connections by searching Wikidata directly, improving existing entries, adding missing information, or asking broader questions across the data through the Wikidata Query Service.
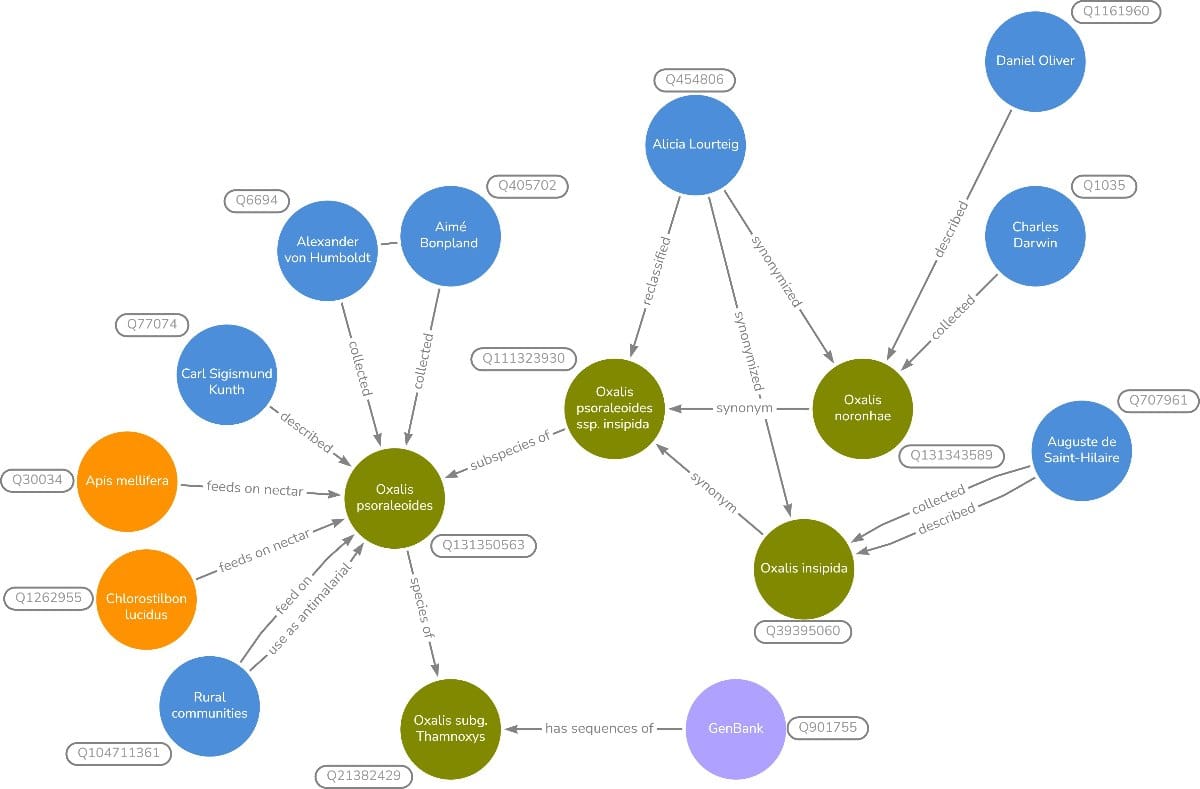
Wikidata does not replace specialist databases, herbarium catalogues or taxonomic expertise. Its value is in helping them speak to one another, making botanical information easier to find, check, reuse and expand. For anyone working with digital plant data, it is a way to build bridges between scattered pieces of knowledge and leave them in place for others.
Herbariograph: sorting the hidden mess of herbarium images
Digitised collections do not contain only neat herbarium sheets. They can also include illustrations, microscope slides, text pages, occluded specimens, corrupted files and many other image types. Before researchers can use these images, they need to know what is actually in the pile. This is where Herbariograph comes in.

Herbariograph, developed by Fabio Andrés Ávila and colleagues, is a deep-learning tool designed to recognise common image types in collection databases. To build it, the researchers created an open dataset with 17 image categories, each represented by 12,288 images gathered from 43 institutions. They then trained an image-recognition model to distinguish between different kinds of botanical collection images, including ordinary herbarium specimens, illustrations, microscope images, text, live plants, damaged files and other problematic images. In practical terms, Herbariograph can sort large batches of collection images before researchers or curators begin more detailed work.

This makes it useful as an early step in digital herbarium work. A leaf-trait researcher may need only standard specimen sheets; an AI researcher may want to remove illustrations or corrupted files; a curator may want to flag low-quality images. Instead of opening thousands of files manually, Herbariograph can do the first round of sorting. It does not replace human judgment, but it can make the road from “millions of images online” to “the right images for this question” much shorter.
Expert-verified datasets: teaching AI with better herbarium images
Automated plant identification sounds like the kind of thing that should become easier once millions of herbarium specimens are online. But there is a catch: artificial intelligence models are only as good as the images and labels used to train them. If the dataset is unbalanced, full of duplicate records, or contains outdated or doubtful identifications, the model is prone to learning the wrong patterns. The pipeline developed by Jed Arno and colleagues tackles this less glamorous but essential step: how to build reliable image datasets from digitised herbarium collections before asking AI to identify plants.
The pipeline samples digitised specimen images through GBIF, preprocesses them, balances the representation of different taxa, and adds taxon labels that can then be checked by experts. The team tested it on two plant families: Cyperaceae, a difficult monocot group, and Rhamnaceae, a eudicot family. They used the datasets to train deep-learning models at genus level in both families, and at species level in Bulbostylis and Ziziphus. In the tests, the model’s first suggested genus was correct at least 72% of the time. The correct genus appeared among its top three suggestions at least 88% of the time, and among its top five with at least 92% accuracy. At the species level, the first suggestion was correct 65% of the time for Bulbostylis and 72% for Ziziphus, rising to 89% and 90% when five suggestions were allowed.

The value of this pipeline lies in helping taxonomists work at larger scales. A curator or researcher could use it to build a cleaner image dataset, train an identification model and generate suggested names for many specimens. These suggestions would still need expert judgement, especially in difficult groups, but they could help prioritise work, flag likely errors and speed up routine identifications.
Together, these tools show that digital botany is not only about putting specimens online, but about making them easier to find, sort, connect and use. None of these tools removes the need for botanical expertise. Instead, they help that expertise go further: across more specimens, collections and questions than any one person could handle alone.
LEARN MORE:
Ávila FA, Park JY, Feder L, Little DP. 2025. Herbariograph: a deep‐learning tool to classify specimen images. New Phytologist. https://doi.org/10.1111/nph.70447
Arno J, Morel J, Rasaminirina F, et al. 2025. A pipeline to compile expert‐verified datasets of digitised herbarium specimens for automated plant identification to accelerate taxonomy. Plants, People, Planet. https://doi.org/10.1002/ppp3.70149
von Mering S, Leachman S, Santos J, Meudt HM. 2025. Wikidata for botanists: benefits of collaborating and sharing Linked Open Data. Annals of Botany 136: 491-511. https://doi.org/10.1093/aob/mcaf062




{kind=link}
.jpg?ref=botany.one){kind=link}