

Have you ever heard of genebanks? They are priceless collections of crop samples around the world. Some genebanks focus on a particular crop, such as bananas in tissue culture, while others might specialise in seeds or a specific method of how the specimens are stored, either in the field or in vitro.
These organisations are dedicated to long-term conservation of crop diversity for future generations whilst also ensuring accessibility to the current generation. In other words, they do not simply store plant material away for safekeeping, but they make it possible for researchers, breeders and conservationists to find, request and use that material. These collections harbour many answers and also questions regarding agricultural biodiversity conservation, plant breeding, global food security and more.
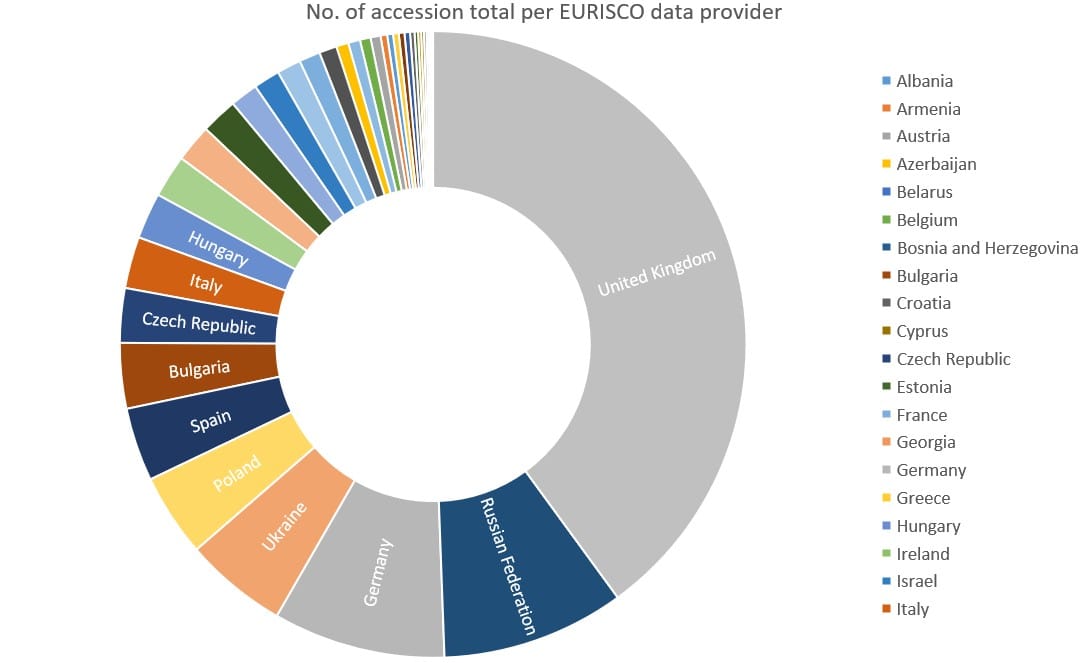
There are almost 900 genebanks worldwide that house approximately 5.9 million individual collections (or accessions), with more than 2 million accessions conserved only in Europe.

These treasure chests are amazing resources and require constant work and resources to assemble and maintain them, and make them useful. Alongside the physical plant samples, genebanks also need to compile, clean and manage the data associated with each accession so that we can properly interrogate these collections. This now includes increasingly rich “multi-omics” data: information from genomics, phenomics, metabolomics and other approaches that help describe a plant’s genes, traits and biochemical make-up. Linking these data to genebank accessions can greatly increase their value for research and plant breeding, but it also creates new challenges for data management, standardisation and long-term use.
If you have ever bought a plant from a garden centre, you may have noticed a label, barcode or plant passport code travelling with it. That information helps identify what the plant is and where it came from. In genebanks, “passport data” plays a similar role, but at a much larger scale: each accession needs a reliable record of its identity, origin, collection history and availability before it can be found, shared and used.
For our Digital Botany Focus Issue, Botany One interviewed Dr Stephan Weise, who is coordinating the European Search Catalogue for Plant Genetic Resources (EURISCO), an information system that provides data for millions of accessions from more than 400 institutes across Europe.
Could you briefly introduce your background and your current role in genebank data management and in the coordination of EURISCO?
I am the head of the Genebank Documentation research group at the Leibniz Institute of Plant Genetics and Crop Plant Research (IPK). Our institute operates the German Federal Ex Situ Genebank for Agricultural and Horticultural Crops. My educational background is in information technology. I studied Business Information Technology and completed my PhD in integrative bioinformatics. A key focus of my thesis was on the integration and quality of life science data. These are topics that have since become increasingly important in my day-to-day work.
In 2014, I was given the unique opportunity of coordinating the European Search Catalogue for Plant Genetic Resources (EURISCO) on behalf of the European Cooperative Programme for Plant Genetic Resources (ECPGR). EURISCO is an aggregator information system that provides a central entry point for information on Plant Genetic Resources (PGR) accessions held in more than 450 European institutes, as well as in several neighbouring countries.
This involves collating passport data and, to some extent, phenotypic observations [observable traits, such as plant height, seed colour or disease resistance] from more than two million ex situ accessions and in situ crop wild relatives (CWR) populations from 43 countries, which are regularly updated in collaboration with highly dedicated colleagues in the respective countries. The size of the respective collections ranges from a few hundred to more than a hundred thousand samples. Overall, EURISCO provides an important overview of the plant material that is available for research and breeding purposes in principle.

From your perspective, what are currently the main bottlenecks along the pathway from field germplasm collection and initial labelling to accessioning, passport and characterization data curation, permit documentation, the creation of the first digital record, ultimately leading to data inclusion in EURISCO?
The more and the better the available data, the better the plant genetic resources described by them that can be utilised for research and breeding. However, given the already limited time and staff resources in many institutions, working with data understandably often takes a back seat. From a data manager’s perspective, this means that both passport data and phenotypic data are often not available to the extent that would actually be desirable. In particular, the compilation and curation of phenotypic data is usually very labour-intensive. This naturally also has an impact on the data available in EURISCO.

This is where genebank data becomes both powerful and difficult. A single record can tell us what a crop accession is, where it came from and how it behaves. But to compare records across hundreds of institutions, the data needs to be complete, accurate, up to date and recorded in ways that other systems can understand. What are the key challenges and future ambitions in integrating such diverse and varied datasets into a central database such as EURISCO? What can be improved to ensure that accession-level data are both widely available and of high quality, while remaining standardised and interoperable?
Challenges include, for example, filling gaps in data on collections that have not yet been documented in EURISCO, as well as improving the quality of the data provided. Data quality encompasses aspects such as completeness, accuracy and up-to-dateness. My group is currently working on defining a framework of metrics that will enable us to identify quality issues more quickly and comprehensively than before, and thus gradually improve data quality in a targeted manner.
Another key challenge is the comparability of data. In the field of passport data, data standards are in place and widely accepted. For phenotypic data, however, whilst exchange formats do exist, there are no widely adopted standards governing the collection of such data, including metadata. Although there is a wide variety of crop-specific proposals and recommendations, in practice, these have very often been adapted to meet the specific requirements of individual genebanks. This limits the comparability of data and, moreover, makes it very difficult to present data to users of the system in a clear and appealing format. In future, greater efforts must be made to raise awareness among experimentalists and data providers and to persuade them to adhere more closely to existing recommendations. At the same time, new methods for bringing existing data into relation with one another need to be considered, despite all the difficulties involved. This would also help to ensure that PGR [Plant Genetic Resources] data complies more closely with the FAIR principles (Findable, Accessible, Interoperable and Reusable).
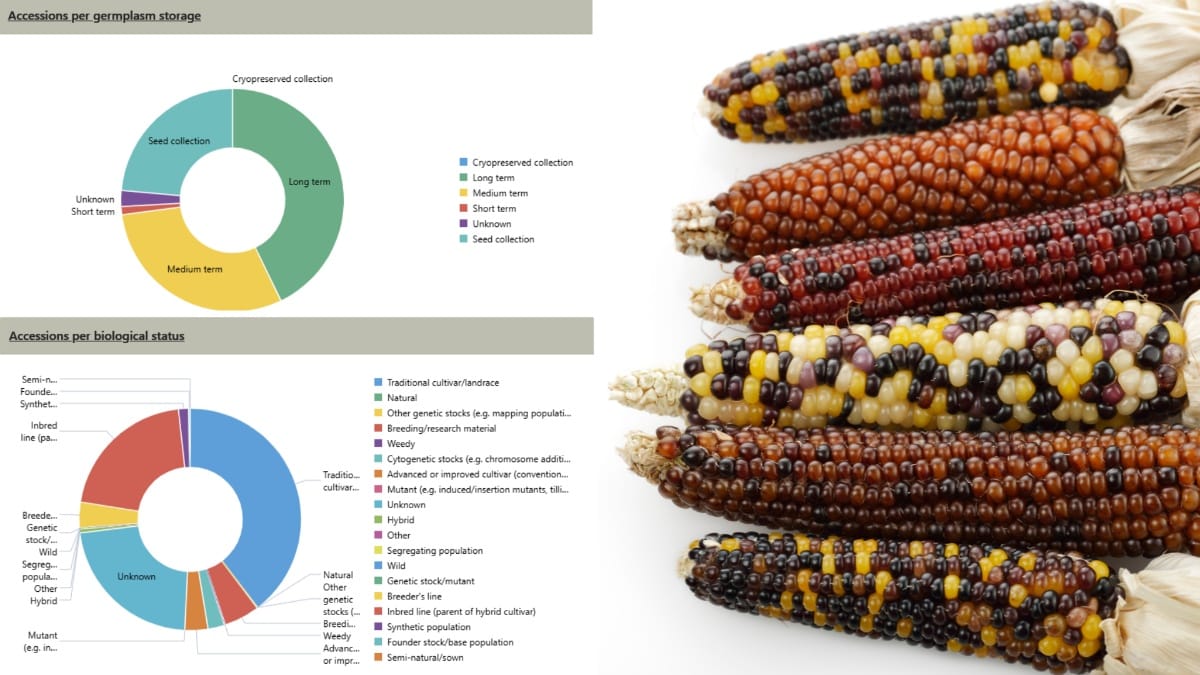
The future of genebanks is not only about storing seeds or plant material. Increasingly, it is about connecting those physical resources to digital layers of information: genetic data, trait data, images, observations, provenance, availability and tools for analysis. In a recent paper you authored on the history and mission of the German Federal Ex Situ Genebank, you describe its transition towards becoming a ‘bio-digital resource centre’. Could you elaborate on this concept and what it implies in practical and strategic terms?
A few years ago, IPK decided to gradually transform its genebank into a bio-digital resource centre. In concrete terms, this means transforming the genebank into an integrated scientific and technical infrastructure in which biological material (seeds, tissue, DNA samples, etc.) is closely interwoven with a comprehensive digital data architecture. My research group is playing a part in this.
This involves elevating existing data to a higher level by comprehensively curating it and enriching it with further information. In addition, data from other domains, such as genotyping data, is increasingly being tapped and linked to traditional genebank data. Tools for visualising and analysing such integrated data are also being developed. All of this is being done to describe plant genetic resources ever more effectively, to optimise their use for research and breeding purposes.
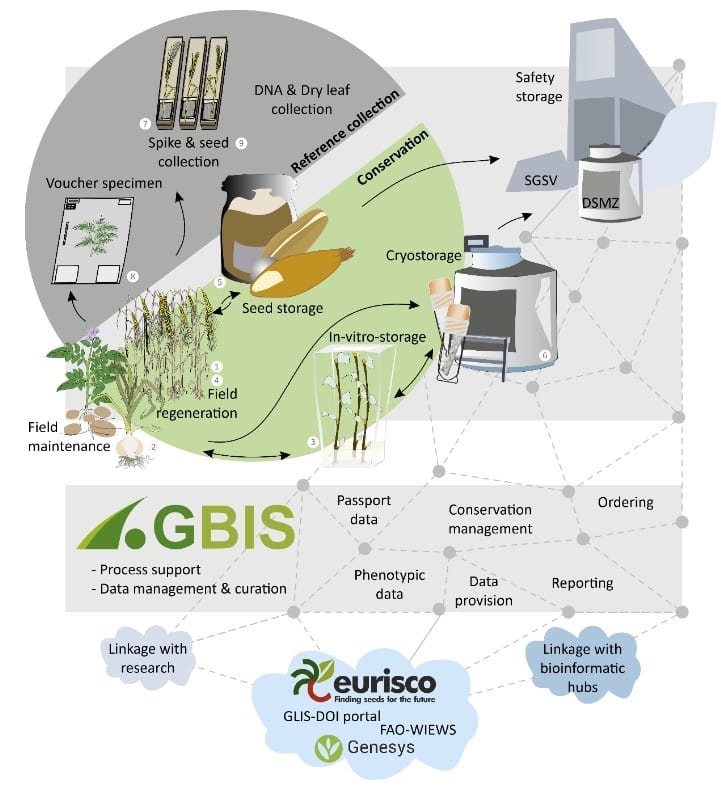
Are there plans to strengthen connections between genebank data and information generated by other types of plant collections, such as in situ conservatories, field collections, herbaria, conservation and restoration seed banks? What would be required, technically and institutionally, to make such integration feasible?
Under ECPGR, for example, work began a few years ago to expand the EURISCO aggregator system so that, in addition to material from ex situ collections, it can now also document material preserved as in situ CWR [crop wild relatives] populations. This can also be extended to other conservation types. From an IT perspective, this is feasible with a reasonable amount of effort. The same applies to linking information from the various fields. A major challenge here, however, lies in the consistent use of unique identifiers [stable digital labels that allow records from different systems to refer to the same accession], without which integration and linking are not possible. Technical solutions exist for this, such as DOIs for plant genetic resources; unfortunately, however, these are often not yet used worldwide to the extent that would be desirable. Furthermore, the major conservation networks are naturally called upon here; they must be prepared to collect and provide the necessary data.
Thanks, Stephan, for the great discussion and for sharing your thoughts on the future of genebanks and their data! Conserving and sharing these crop collections, together with the widest possible range of high-quality data for each accession, is key to providing diversity to researchers, farmers and breeders, and ultimately to consumers, to build a more sustainable and productive agricultural system. EURISCO and its efforts to integrate data from genebanks, wild plant populations and phenotypic characterizations are certainly a big step in this direction.
Genebanks are often described as treasure chests of crop diversity, but this interview shows that the treasure is only useful if people can find it, understand it and connect it to other information. Could this little plant, tucked away in the corner, help breed a more resilient crop? Does it carry useful traits for drought, disease resistance or nutrition? Is it already well documented, or is it still waiting for the right data to make it usable?
This is why databases such as EURISCO matter. They help turn millions of conserved crop accessions into something researchers, breeders and conservationists can actually search, compare and use. They also reveal why digital botany is hard work: the challenge is not only storing plant material, but describing it clearly enough that someone else, somewhere else, can understand what it is and why it might matter.
So, if you have a few minutes, try exploring EURISCO yourself! Search for a crop you eat often, such as rice, wheat, potatoes, or beans. Look at how many accessions are held, where they come from, and what kinds of information are available. The charts and records may look simple at first glance, but behind them is a huge international effort to make crop diversity findable - and to keep future options open for farming, food security and plant science.
READ MORE:
Weise S, Blattner FR, Börner A, et al.. 2025. The German Federal Ex Situ Genebank for Agricultural and Horticultural Crops – Conservation, exploitation and steps towards a bio-digital resource centre. Genetic Resources: 91-105. https://doi.org/10.46265/genresj.gydy5145
Guest Writer
Filippo Guzzon is a plant biologist working on seed biology and genebank management, with a side interest in ethnobotany. He has worked with different organisations across Europe, Latin America and the South Pacific, and he is currently based at the Millennium Seed Bank of the Royal Botanic Gardens, Kew (UK).
Spanish translation by Filippo Guzzon.
Cover picture by IPK Leibniz Institute / A Kartsen.
Updated June 24.
Title to How to Keep Track of 2 million crop accessions collections, as it's 2 million accessions from 400 collections.



