


Anyone with a smartphone probably has a camera roll of images waiting to be sorted through. Now imagine you have millions of images to process, and associated data to manage, and some of them include labels handwritten with a quavering hand by candlelight over 200 years ago by a botanist who can’t quite spell breviauriculata…
Digitisation means giving each specimen a digital identity: barcoding it, photographing it, and turning the information on its labels into easily searchable data. Before digitisation, much of this material could only be fully explored by people able to visit the collections in person or work directly with the specialists who knew them best. Digitisation promised something different: the chance to make specimens browsable, visible and useful to researchers, students and plant lovers around the world.
This daunting challenge faced the Digital Collections team at the Royal Botanic Gardens Kew, when they secured the essential DEFRA funding in 2021 to digitise their herbarium collections in just four years. At its peak, the team was imaging around 100,000 specimens a week.

Since 2022, they have barcoded, catalogued, imaged, and transcribed 7.3 million herbarium and fungarium specimens. Following the conclusion of the project in March of this year, Botany One interviewed the team that masterminded this initiative and carried it through to the end: Sarah Phillips - Senior Digital Collections Manager, Marie-Helene Weech - Lead Digitisation Operations Manager, and Laura Green - Data and Imaging Manager.
For many users, the digital image becomes their first point of access to the specimen, so quality really matters. How did you strike the balance between achieving consistently high image standards and working within a project budget?
Green: The key thing is to know what you are aiming for and what quality levels you are willing to accept before you start. Obviously, you want to get really high-quality images, but at the same time, you do not want to grind the project to a halt. We already had general standards that were decided during the Global Types project, things like capturing at 600PPI [number of pixels within one inch of an image displayed on a computer monitor]. We turned to the FADGI standards and Metamorphoze guidelines to have more of a quantitative approach.

Kew opted to use a third party company for the bulk of their specimen digitisation and transcription. For readers less familiar with herbarium digitisation, this means capturing both a high-quality image of the specimen and key information from its labels. How did you find working with a third party supplier for transcription of data?
Phillips: On previous digitisation projects we wrote very strict guidelines on what would pass or fail. This time [due to the high number of labels needing transcribing] we were a bit more flexible with it. You need to keep in mind that the transcriber is not doing any interpretation, just verbatim transcription, so you need to be realistic about what you expect from them. If the text is printed, they should be able to transcribe it as written, but handwriting can be tricky. We did produce a lot of guidelines for them, and kept an open line of communication to raise queries directly with our team, and they were very responsive to that. We knew it was not going to be the final polished thing, because if you want a perfect transcription, it is going to take ten times as long. We might have a lot of blanks in the “country” field, for example, because we didn’t want them guessing incorrectly. We do have plans to gradually fill in the data that wasn’t fully transcribed through other means.
Weech: I was looking at a spreadsheet of corrections from Kew’s Data Portal that somebody sent in to us this morning. It was really nice to see that people are actually using our data and looking at it properly. I was actually quite impressed by how close the transcribers got to the correct information. I think they did pretty well!

Once the images and label text had been captured, the next challenge was making sure the data followed agreed standards so it could be searched, shared and reused. This is the less visible part of digitisation: turning millions of individual specimen labels into structured data that can work across different databases and global biodiversity platforms. Which Metadata standards posed the biggest challenge to meet for Kew?
Phillips: We used Darwin Core Archive [a common biodiversity data standard that helps specimen records from different institutions be shared and understood in the same way] and then we have our own standards for the Integrated Collections Management System (ICMS), which aligns with DwC-A but contains a lot more data. We also aligned ourselves with Minimum Information about a Digital Specimen (MIDS). The challenge came with how the data was gathered and matched to the fields; it required several steps of formatting and data cleaning. We have put out the data, knowing there are issues, but the Global Biodiversity Information Facility (GBIF) is quite good at flagging some issues, so we get feedback from aggregators and users of our data.
Weech: We are aware of lots of errors in fields such as coordinates. Nicky Nicolson (Intelligent Data Analysis lead) is looking at Georeferencing and identifying outliers, and that’s just one of the ways we can solve many of our coordinate problems. In some cases, there will be a need to revisit the data visible in the image; in some ways, having to find the physical specimen was our most rate-limiting step.
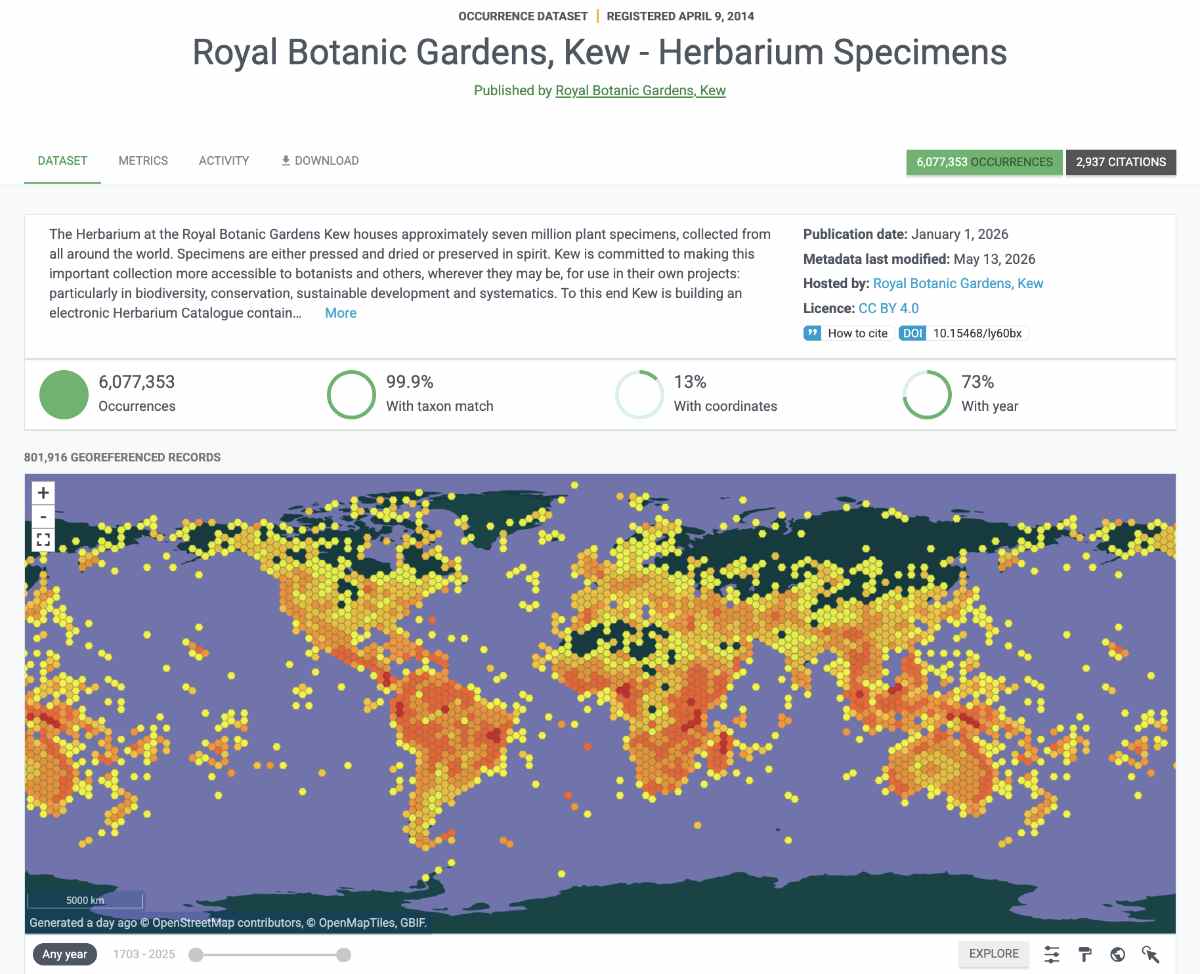
This also means that digitisation does not end when the specimen is photographed or transcribed. Some errors only become visible once the data is used, mapped or compared at scale.
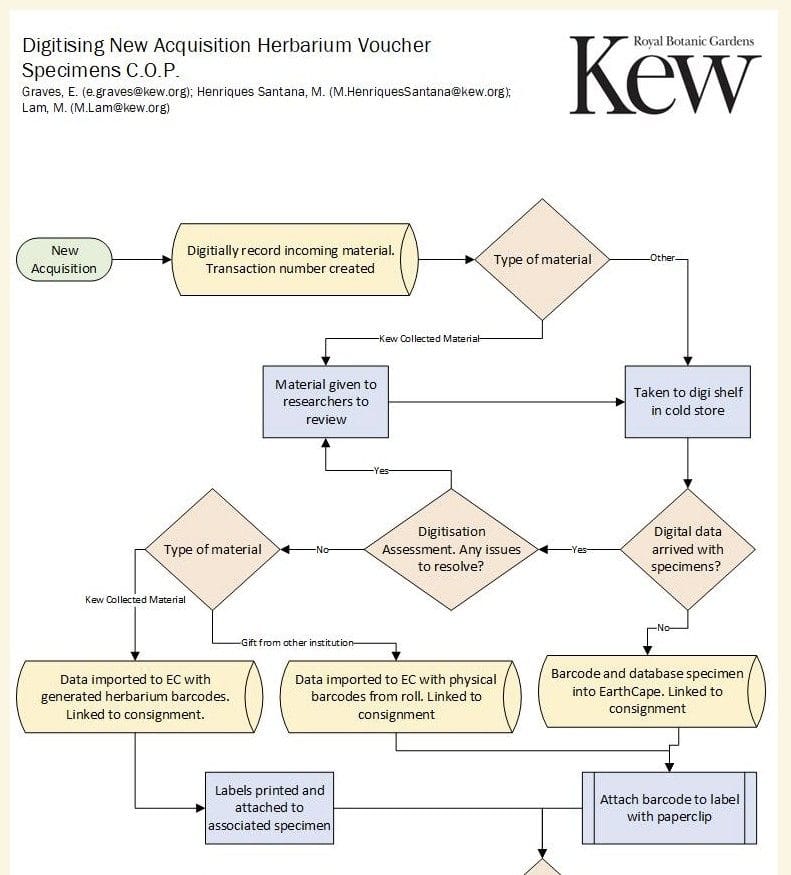
Digitising millions of specimens is not just a technical challenge; it also means designing repeatable workflows for different teams, tasks and quality checks. How important was workflow design in this project?
Phillips: We had to upscale our team very quickly, so we continually reviewed and adjusted workflows. We had specialised workflows for our in-house and supplier teams, and they required a lot of training and supervision. We were doing it at a speed and volume that seemed a bit crazy at times, but we did have a lot of experience and a strong core team to build from.
After working at such a large scale, did the project change how you saw the collections themselves? What was the most surprising thing you learned over the course of this project?
Weech: We had a few more Darwin specimens than I expected! We had a group chat where digitisers could post whenever they found a Darwin collection to let the curation team know. We would usually get the same Darwin specimen out for tours and displays, whereas now we could get a whole variety out!
Green: Just how many people were involved in this project by the end? Coming from such a small team, where we were digitising things on a much smaller level, to then having so many people working together was a bit wild, really! It’s when we would have parties that we would see just how many people worked together to achieve it.
Phillips: I agree. When you are in the thick of it, you are thinking about workflows and management, but you also need to manage your team and make sure that they are happy. There were lots of people thrown in the deep end, but we always managed to come together to get the task done.
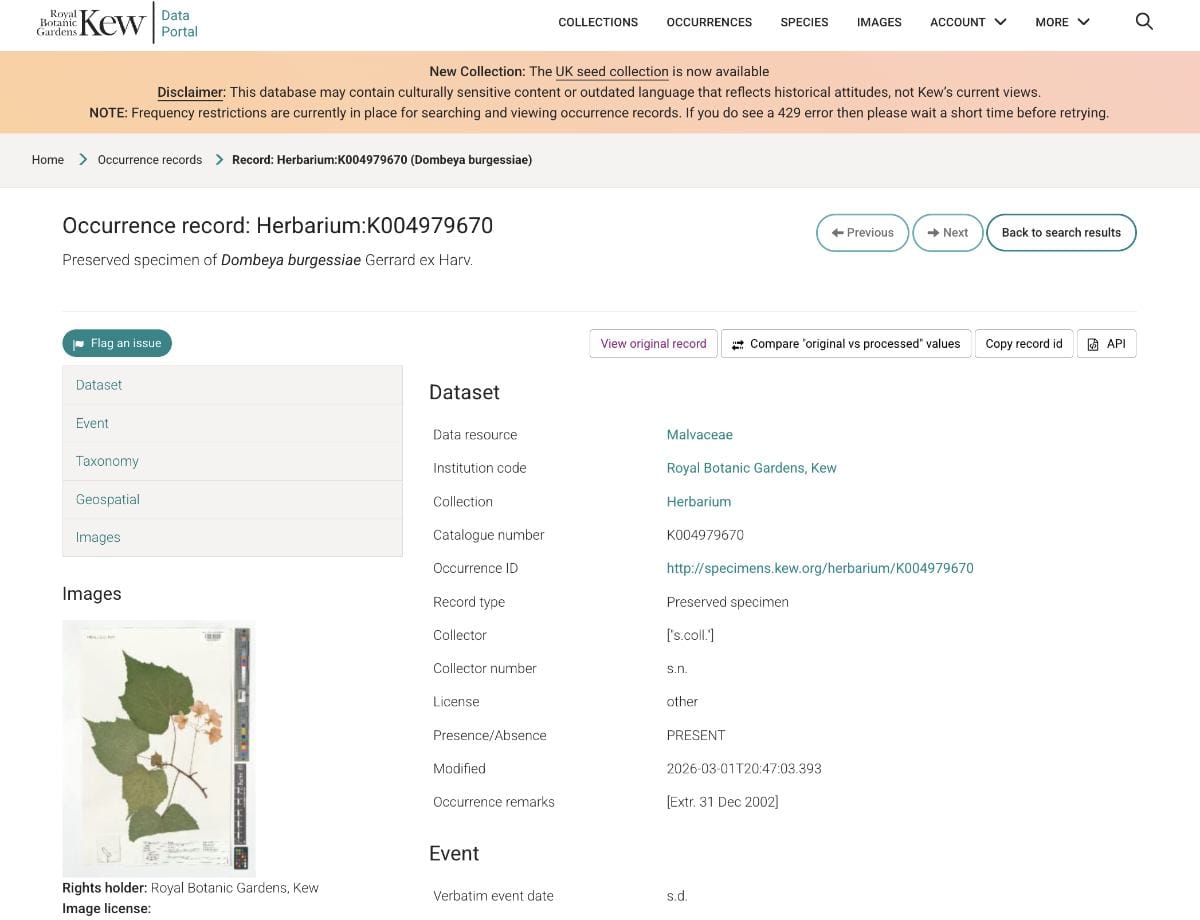
Mass digitisation can sound technical, but at its heart, this project is about opening up Kew’s collections to more people. Millions of herbarium and fungarium specimens – some familiar, some unexpected, some still needing further checking – can now be searched, studied and connected in new ways across continents.
For researchers, this means faster access to specimen records, images and label data. For plant lovers, students, historians and curious browsers, it is a chance to explore one of the world’s great natural history collections from anywhere. The project also shows that digitisation is not a single tidy step: it involves people, workflows, standards, quality checks, interpretation, and plenty of problem-solving along the way.
So, have a look around Kew’s Data Portal. Search for a plant you know, a place you love, or a collector you have heard of. You might find a specimen collected decades or even centuries ago – now newly visible, newly searchable, and ready to be part of new stories!
LEARN MORE:
Graves, E., Phillips, S., and Hill, B. (2024) Streamlining Workflows for the Digitisation of New Acquisition Herbarium Specimens: Meeting Archive Service Accreditation Standards amid Mass Digitisation. Biodiversity Information Science and Standards, 8. Available at: https://doi.org/10.3897/biss.8.138737.
Wright, I., Bowles, B., Murphy, B., Paton, A., Liu, U., Weech, M. H., ... & Adcock, J. (2026). RBG Kew Science Digitisation Project 2026. Delivery experience and lessons learnt. Available at: https://doi.org/10.34885/s29k-4z53
Guest Writer Profile
Magda (she/her) is a British/Polish ecologist currently based in London, UK. Trained as a field ecologist, she made the pivot to herbarium digitisation and curation in 2023. This has taken her from Royal Botanic Gardens Kew, to the South London Botanical Institute, and she will be joining Trinity College Dublin this autumn.
Cover Image: A digitiser working on boxed palm specimens at an imaging station. Source: Magda Upton



