


What name do you go by? Does everyone call you the same name everywhere you go? Probably not, and the same stands for plants. The names we give plants can vary depending on our relationship to them, what we use them for, where they grow, and the properties they have. This cultural aspect of plants is a simple way for us to connect with nature, whether through foraging for a specific plant, or simply observing a new plant that has sprung up in our garden. However, common names of plants can often be misleading or overlap with common names of other plants. This can pose a challenge when you are looking for a “mayflower” (Epigaea repens), your friend is thinking “mayflower” (Cardamine pratensis) and your other friend is thinking “mayflower” (Crataegus laevigata).
To communicate effectively about a plant, accurate naming is key. To understand some of the issues linked to naming discrepancies, Botany One interviewed Dr Bob Allkin, programme manager of the Plant Use Informatics team at the Royal Botanic Gardens, Kew. This interview has been edited for clarity and brevity.

You have spent much of your career at the Royal Botanic Gardens, Kew, working at the intersection of taxonomy, biodiversity informatics and useful plant knowledge. Could you tell us a little about your career journey and how you became involved in digital botany?
As I think happens with most people in their careers, it was largely accidental and opportunistic. I had done no biology at all at school, but then decided I wanted to study biology at university, and I fancied doing marine biology. I signed up for courses at Queen Mary College, where you could mix and match courses from different disciplines. I was frightened of not being able to keep up with biology because I hadn't done any before, so I mixed some maths, some computing, and some chemistry in with the biology and ended up with a combined honours degree. In my second and third years, I focused on biology, but the maths came easily to me; it’s what I was good at, and that opened the door to do a PhD at the Natural History Museum. My challenge [during the PhD] was to enhance the ways that we use computers to build identification tools.
For centuries, botanists and zoologists have written identification keys, which are effectively decision trees, that are a very poor way of organising information. They do not really work if, for example, the first question is “does the plant have a white or red flower?” and the plant that you're looking at does not have flowers. The objective of these systems was to try to facilitate the interaction between the computer and the individual trying to identify the plant or the insect, and enable them to say, “Well, I don't know what the flower colour is, but the roots are like this, and I'm in France, so what should I look at next?”

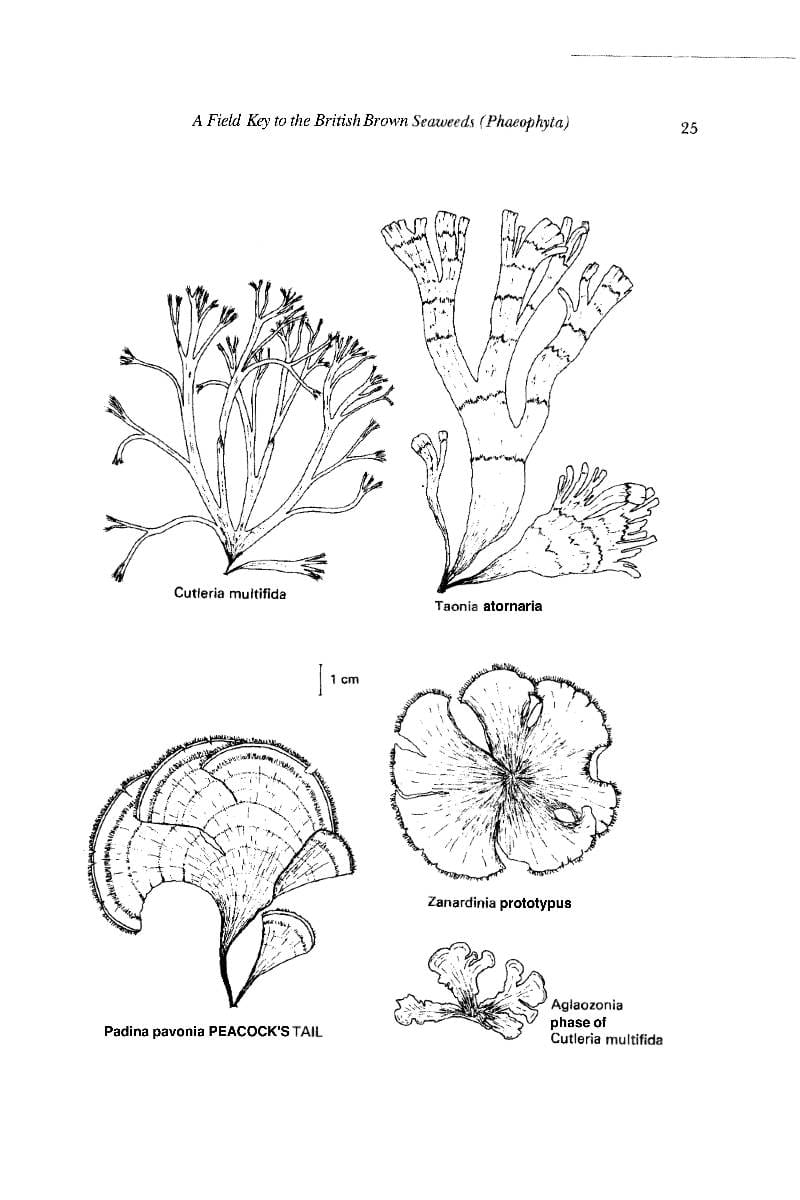
Dichotomous keys are frequently used in botany for the identification of plants. Here is an example of an illustrated field guide to seaweeds, including a decision tree-style key. Source: Field Studies Council.
My research was more mathematical and logical. It focused on what makes a good diagnostic character, or set of characters, to make those sorts of [identification] systems work. Then I went to Mexico, which was life-changing because I learned to speak another language fluently and realised that people think differently in other languages. I fell in love with Mexico, and Latin America generally. Using the same tools that I'd been working on, I built a small team devoted to creating a dataset of the plants of one state: Veracruz.
I wanted to provide tools for the students and herbarium staff to identify the plants to at least family/genus level. Through this process, I realised just how difficult that was. These tools were designed to make it easier for the person identifying a plant, but they required a huge amount of effort on the part of the expert botanist to put their information into these formats. The format that the data was stored in was awful, so no one was actually using it. Then I became more interested in data structures.

That led me to a post-doc at the University of Southampton, where we initially built a database of the Vicieae [now tribe Fabeae], which is a tribe of the legume family including peas, lentils, and vetches. We used existing software to show that this could be done for all 450 species in terms of the chemistry, geography, and morphology of these plants. That Vicieae project then became an international consortium for the whole legume family, eventually the International Legume Database and Information Service. In some ways, this was the first time I began to think about who our users are and what they needed from us. I was left dissatisfied, and I remain dissatisfied today with how unwilling botanists are to work out what information non-botanists might actually be interested in, and how they want that information expressed.
To build a database is obviously hard work. My very first research publication, based on the work in Mexico, was around the multiple uses of data. You don't [build a database] for just one purpose, and one audience, that would be silly. And yet, I don't think it's fully comprehended or understood that you want to do different things with that data, and that also has implications about how you store it and the words you might use.
I like to use the example of writing an identification aid for plants that my grandmother could understand. She had a poinsettia in our front room. As far as she's concerned, it's got red flowers, but of course, a botanist would say it does not have red flowers, because those are bracts, and the flower is minute and white. There are two versions of that reality and if you want [the identification aid] to serve its intended purpose, you need to be aware of that and think about how you store that information.


Poinsettia (Euphorbia pulcherrima) has showy foliage which is often interpreted as flowers. The true flower is inconspicuous and unassuming. When describing plants, it is important to keep in mind the level of background knowledge and context of the user. Sources: Berthe Hoola van Nooten | Meneerke bloem via Wikimedia Commons (CC BY-SA 3.0)
I had the privilege of working for the Department for International Development (DFID) as a Technical Cooperation Officer. I spent just over five years in north-eastern Brazil running a programme in local communities, looking at rural development and what we could do to enhance the lives of the people living there. I was taken into communities where our NGO partners were already well known and were running workshops with farmers who were very knowledgeable about the plants, but in many cases, were illiterate. So we communicated very visually and found different ways of engaging with them, like using pebbles or plants. When we got them to prioritise where their information requirements were, medicinal plants came out top or second. If it was not medicinal plants, it was forage for their goats during the long dry season. It became evident to me that we were not communicating well. Science and research are only useful if they are communicated in a way that can be understood by the people on the ground, so to me, that is where we have to focus more. It comes back to the human dimension, really talking with people, and understanding what they're trying to do rather than assuming.

You have been involved in major efforts to organise and standardise plant information, including work on useful plants, medicinal plants and global plant databases. What have these projects taught you about the strengths and weaknesses of current botanical data infrastructure?
There are many successful applications of the wonderful new world of technology. Following my PhD, I was very sceptical that these computer-assisted identification tools were ever going to work. I could not see them doing it, not because of the diversity of species, but because of the lack of data. The way I had framed it in my head was a big data matrix with complete descriptions of every plant, before you can start. But now with plant identification apps on our phones, we can just take a picture, and they’re fabulously good. So there are technological successes, including the volume of data and our ability to share it globally.
During my PhD, I was lucky enough to have been lent a modem. It was a big wooden box into which you put the phone head and clamped it down to send information down to another computer. Whereas now we are part of a digital world where we are sharing information easily, so the technology has certainly made huge advances. Where we still struggle is the lack of awareness from scientists and science managers of the importance of data and its longevity. I have seen many worthwhile database projects come and go. Huge amounts of energy and effort are poured into building a database, until the funding runs out, and five years down the line you can't see [the database] anymore. I say to some of my colleagues at Kew that I can walk into the herbarium and read the letters written by the director in 1880 and see what he had to say, but I cannot access data that was built in a database by a colleague of mine 10 years ago because that technology is no longer available. They encoded the data, and only they know what those codes are. Every time a project builds a database, we should absolutely be making sure that we know what its future is. We should be incorporating metadata because we cannot look after data in the same way that we look after specimens. It is my firm and fervent belief that we are doing a disservice to the world by not looking after our data better.

One of your most exciting current projects is the forthcoming Plants for Health portal. Could you tell us what it is, why it was created, and what problem it is trying to solve?
Plants for Health is much more than a website. The website is one of the products from the project. For example, we are providing data services built upon that same dataset, presenting the information in different ways. It builds upon a previous project, an additional plant name service that has been running for 14 years at Kew, which we started from scratch. We could only do this at Kew because it builds upon Kew’s taxonomic and nomenclatural resources: the International Plant Names Index (IPNI); the World Checklist of Vascular Plants (WCVP); Index Fungorum; and Species Fungorum. Those are absolutely core to what we do!
They are core to all of data management at Kew, from the digitisation project to providing access to information that we hold in old herbals, and that information is shared through global resources, such as World Flora Online or Global Biodiversity Information Facility (GBIF). These core data, the scientific names and their synonymy, and how they fit into a hierarchy, are equally important to people working in other disciplines, but they do not know that [these resources] exist. They do not know the difference between IPNI and WCVP. They will go to IPNI expecting it to provide them with information around synonymy, which it doesn't do, because it wasn't designed to do that. They don't know how to use scientific nomenclature correctly. When I say other disciplines, I'm thinking about ecologists, foresters, rural development and health professionals.
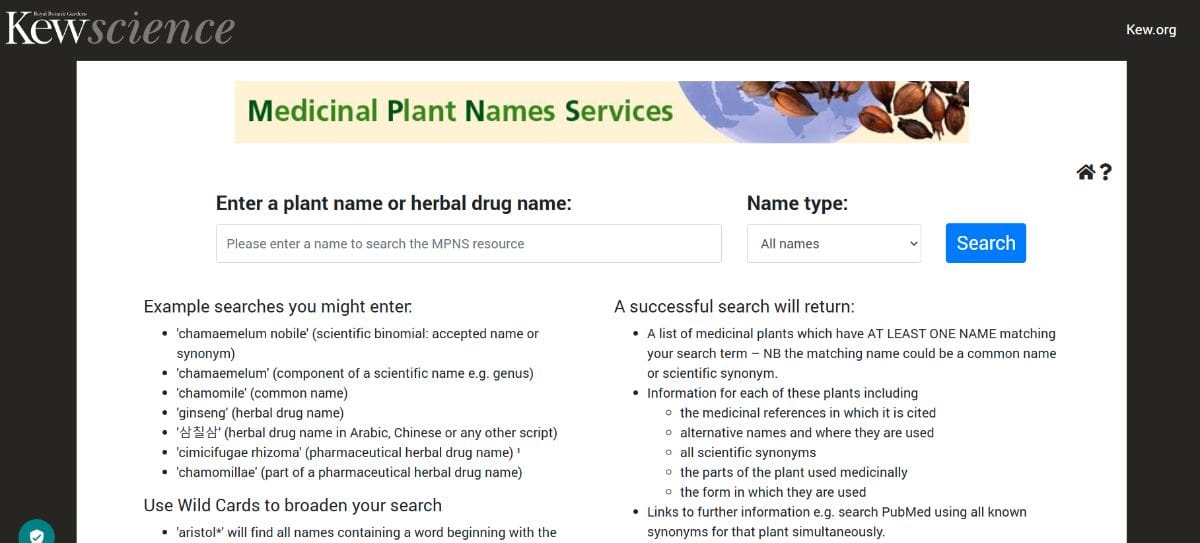
Medicinal Plant Name Service (MPNS), and now Plants for Health, are aiming very clearly at health professionals working with natural products that derive from plants and fungi. We're not an encyclopedia of these species. We are a lookup tool and an index to other people's data.
We have captured the scientific names as used in those publications, along with common, drug and pharmaceutical names, often written in Latin from pharmacopoeias. Herbal drug names can be completely ambiguous; for example, if you search for “ginseng”, you will discover that there are herbal products sold under names containing ginseng in their title, deriving from more than 26 different plants with different chemistries and different uses. That is terribly confusing for the consumer, regulators, and researchers. In scientific literature, you'll see a lot of published chemical research in which it is very unclear as to what plant they were actually looking at because they do not know how to use the scientific nomenclature correctly, and that's where we come in.
We try to fill that gap between botanical knowledge and medical uses. With Plants for Health, our remit is much broader. We are also including food supplements, nutraceuticals, novel foods, personal care products, and fungi of relevance to a much broader set of audiences. Last year, MPNS hit a million different users for the first time. We are the second most visited website at Kew, so that feels like something of an achievement.
The impact is on enhanced research and regulation. If you search the MPNS portal for "ginseng", you find 26 alternative plants. You can explore any of those plants and retrieve everything published about that plant via PubMed using any of its 25 different scientific synonyms. You need to know all of its synonyms to find all the data they hold. MPNS achieves that for you. With the Plants for Health portal, you can extract data from PubChem, PubMed or many of the other data sets and collaborators that are working with us. We can present information from a whole variety of different sources without actually having to store everything ourselves. What we provide is access to the information.

There is a huge amount of information online about medicinal plants, herbal remedies and plant-based health products, but the quality varies enormously. How does Plants for Health approach evidence and reliability?
I think this is very much in the eye of the beholder. I'm not clear in my own mind about how we can assign scientific truth. I have a growing resistance to the insistence on scientific evidence. That is not to say that I don't think that evidence is important. I am a scientist. I believe that we have to have evidence that this actually does work and how.
To explain what I mean, in 1900, the Brazilian Pharmacopoeia covered herbal medicines drawn from about 100 plants. Over the decades, that number kept dropping until there were only about eight plants left by the 1980s. The reason for that was that the pharmacists were becoming increasingly demanding about the level of evidence. They felt uncomfortable including a plant for which there was insufficient scientific evidence. From that point onwards, the number of plants in the Brazilian Pharmacopoeia began to increase and the plants that they were including were primarily Chinese and European plants because they were well studied in Chinese and European research labs.
In Brazil, Chinese medicines are readily available in stores, supported by the Brazilian Pharmacopoeia, because these products have adequate research behind them. However, underresearched traditional medicines will not feature in the Brazilian Pharmacopoeia. This can result in people giving out medicinal plants with good intentions which turn out to be toxic rather than medicinal. There are some very simple things we can do to improve how these plants are being used. I worked with a fabulous chemist, Francisco José de Abreu Matos, in Brazil, who had a project called Living Pharmacies or Farmácia Viva. They were testing plants for efficacy and safety, and promoting the use of beneficial plants. They showed people how to grow them, produce soaps or teas from them. Then the community could use the products themselves, but also generate money by selling them. They were already doing this before we arrived, but we were able to amplify and enhance some of the scientific knowledge going into the project. So I think there are very simple things that science can do without getting too hung up on chemistry.

For us, building a database, we seek to make clear that we are not the source of truth. One of the challenges we face in designing the portal is how to communicate that to our users. They might expect us to be giving them the truth, when all we can do is to report information stored in reputable literature and in regulations. Where there is a misspelled scientific name in a piece of legislation, we have captured it. My botanist colleagues get upset because it's wrong, but the name is used in legislation, and will continue to be used. We must include it to point people to the right name. We include citations from one publication stating that a plant is poisonous, and from another publication stating that the plant is not toxic. Placing contradictory opinions to our users enables them to decide.
We index the information according to mapping tools to enable research. If you wanted to know about using the roots of a certain plant, treating malaria, you can search our database, but not all of the books, reference sources, or regulations that we have compiled will necessarily have used the word “malaria” or the word “root”. What we offer our users is a simplified terminological structure, along with the exact phrase that was included in the original publication. If one publication says this plant is toxic, while other publications say it is not toxic, we present both pieces of evidence alongside each other, because actually, toxicity is really complicated. We just want to expose the information that is available and allow the user to explore this and come to their own conclusions, and we do not erase the common names, because they are part of the language. They are part of people's culture; there's absolutely no way in which you can tell someone that their common name is wrong. What my Gran called a bluebell is not a bluebell in Scotland.


A bluebell by any other name… The English bluebell Hyacinthoides non-scripta (left) and the Scottish bluebell Campanula rotundifolia (right). Sources: Magda Upton
What feedback should flow back from users into global plant databases?
It really does depend on your purpose and the scope of the database. We seek feedback about what is wrong, which sources are key to users’ industries and are lacking in our database. We work closely with partners and validate and enrich their work. For example, an Indonesian PhD student in the UK amassed a huge dataset of 27,000 different scientific names for medicinal plants used in Indonesia. Our role was to help her unpick them. Removing duplicates, misspellings, and synonyms, we ended up with a list of about 6,500 species. She could then focus her conservation efforts on 6,500 and not look at the same plant five times under different names, and we would do the same for anyone using our service. One of the key outputs of Plants for Health is enhanced datasets, enhanced decision-making, enhanced research, in a whole bunch of different partner activities, and that feels good.
Small and in-country herbaria are often closest to the plants, people and landscapes that global databases rely on. How should global digital resources better support, credit, and learn from national and local collections?
There are some obvious points around language and local knowledge. Why should we be focusing on Brazilian plants when Brazil is just full of fantastic taxonomists who know those plants very well? What on Earth can Kew possibly bring to that? It's not so much the global spread that is the problem; it is a disciplinary change. When I worked in north-eastern Brazil, we were regularly inspected by the Department for International Development (DFID) to make sure that we were spending taxpayers’ money correctly. One of the consultants who came regularly was a really nice guy in IT and knowledge management, and he brought me a present of one of those “Mind the Gap” T-shirts. I knew exactly what he meant. Once we'd started that project, everyone said, “Oh Bob, how are you going to manage the communication between Brazil and England? This is going to be really difficult”, but there was no difficulty at all! The taxonomists in the UK speak the same language as the taxonomists in Brazil. They had the same belief set. They talked together using the same terminology. The rural development professionals in the UK and the rural development professionals in Brazil talk with one another beautifully. There is no problem. But if you try to get a taxonomist to talk with a rural development professional and understand one another and agree about what is important, that is where the problems occur.
It is about reaching out from our little world of botany and conservation towards the people who are actually working with these plants and understanding their perceptions, particularly in terms of what information they might need. And I think we still lack that curiosity sometimes about what other people are doing with plants or why they need plants. We have a narrow focus on what matters, and I think that doesn't help us in terms of information management.

Looking ahead, what excites you most about the future of applied botanical data?
I think it has to be the growing interoperability and the possibilities it brings for linking data globally and across disciplines. That is where real opportunities lie, and for an organisation such as Kew, that provides the default terminologies around plants and fungi, there are so many wonderful opportunities for us to be part of networks that need to talk about plants and fungi, but for very, very different purposes, and they do not even know that Kew exists. It does involve technology, but I’m not expecting AI to come up with brilliant new things. It’s us all being part of a global information network that’s really exciting.
The next name you meet
The next time you make a cup of ginseng tea, pause for a second. Do you know which plant species you are really drinking?
The same question could be asked of a chamomile tea, a lavender oil, a “sleep” blend, a herbal supplement, or a botanical ingredient in your skincare. A familiar plant name may point to one species, several possible species, a plant part, a product, a local tradition, or a name that has changed over time.
That is where digital botany becomes more than a technical exercise. It is not just about putting collections online. It is about helping plant knowledge travel more safely between science, medicine, conservation, trade, policy, farming, gardening and everyday life. Somewhere, in a database, a specimen drawer, a field notebook, a regulation, a product label, or someone’s memory, there may already be plant knowledge that could solve a problem. The next task is to connect it.
Guest Writer Profile
Magda (she/her) is a British/Polish ecologist currently based in London, UK. Trained as a field ecologist, she made the pivot to herbarium digitisation and curation in 2023. This has taken her from Royal Botanic Gardens Kew, to the South London Botanical Institute, and she will be joining Trinity College Dublin this autumn.
Cover image: Professor Francisco José de Abreu Matos and Vanessa Sequeira looking at plant material in a Brazilian market. Source: Bob Allkin




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}