

Specialized metabolites are critical for plant–environment interactions, such as attracting pollinators or defending against herbivores. They are also essential for use as pharmaceuticals, cosmetics, nutrition, and for the manufacture of drugs, dyes, fragrances, flavors, and dietary supplements.
The identification of the genes encoding enzymes that produce specialized metabolites is key to engineering their pathways. This engineering approach can be used to modify the structure of the specialized metabolites, or to make completely novel molecules, with new or improved biological properties.
Unlike general metabolites, which are directly involved in the growth and development of a plant and generally conserved among plant species, specialized metabolites are lineage-specific and highly diverse. Many genes that underlie the production of specialized metabolism belong to the same gene families as those involved in general metabolism, which makes them difficult to distinguish.
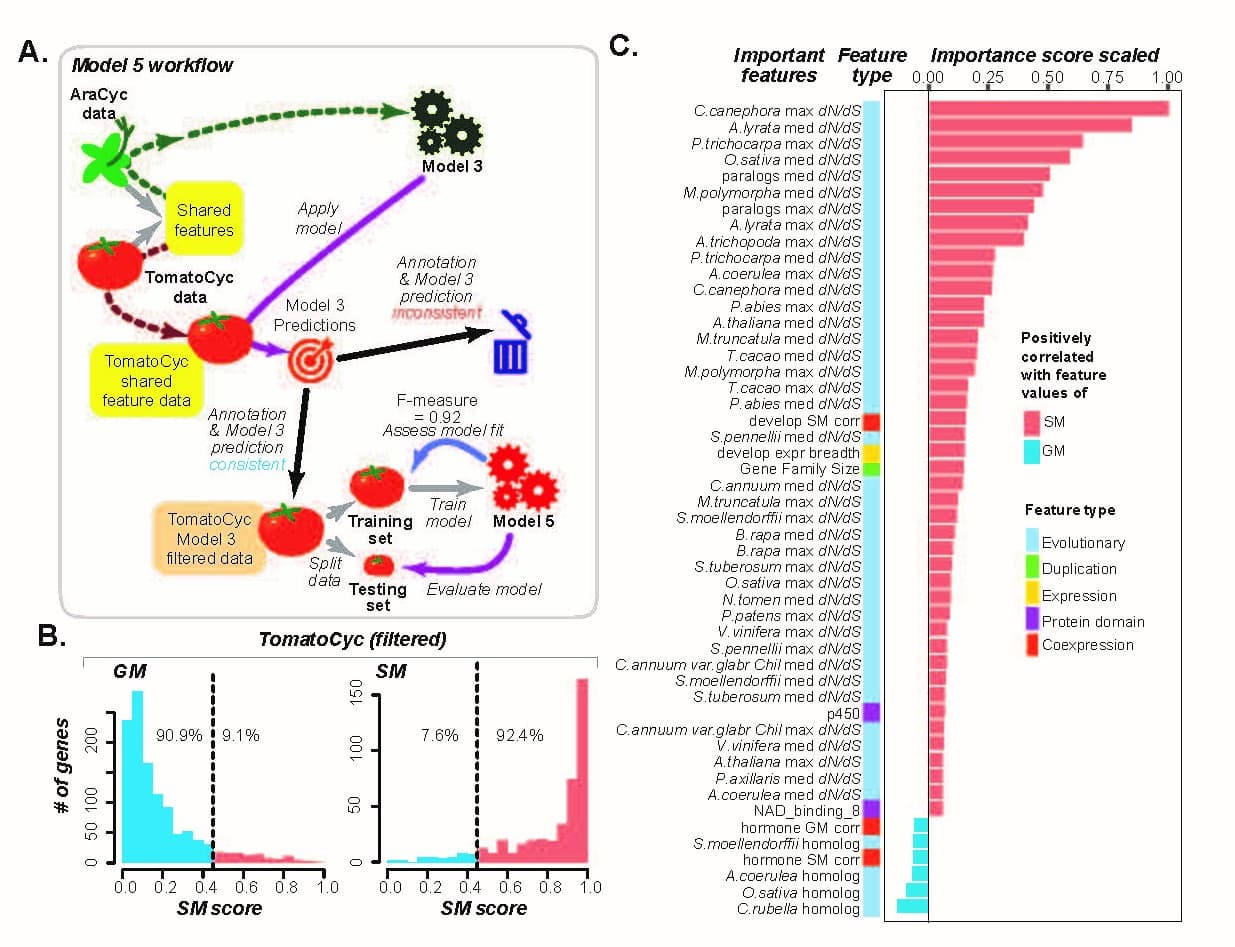
A machine learning strategy, transfer learning, was used to identify specialized metabolism genes in a new study published in in silico Plants lead by Professor Shin-Han Shiu of Michigan State University. With this approach, the authors were able to use knowledge from the well-annotated Arabidopsis thaliana to predict gene functions in cultivated tomato, which has fewer experimentally annotated genes.
“This approach uses the best annotated plant species, Arabidopsis thaliana, to filter out, in some cases, potentially mis-annotated genes in tomato. By training a new model based only on the remaining genes, the model improves substantially. Without this filtering step, mis-annotated genes lead to suboptimal models, which is why we see worse predictions in earlier models based only on tomato data.” explains first author, Dr. Bethany Moore, currently a postdoctoral researcher at the University of Wisconsin-Madison.
The authors caution that while the transfer learning approach worked well for general metabolism genes, but it did not have as much impact on the prediction of specialized metabolism genes, likely because specialized metabolism pathways are by definition specialized–what you learn in one species does not necessarily apply to another. In addition, the potential mis-annotated genes need to be further verified experimentally.
According to Shiu, “the machine learning approach excels at identifying patterns in datasets from many various sources. A good model based on the identified patterns can then be used to make predictions that can be further tested. With more and more data become available, we expect to see wider applications of machine learning in solving plant science problems.”
Software developed for this and other projects are available at https://github.com/ShiuLab.




