

Advances in computing and high-throughput phenotyping have driven massive increases in data availability. Scientists are leveraging this data to predict new outcomes, such as a crop’s response to being planted in a different location, or in the same location with a different climate.
According to a new research article by Dr. Carlos Messina from Corteva Agriscience and colleagues, new modelling approaches should be explored to exploit this trove of data. This article presents several hybrid modeling approaches to achieve accurate and interpretable predictions.
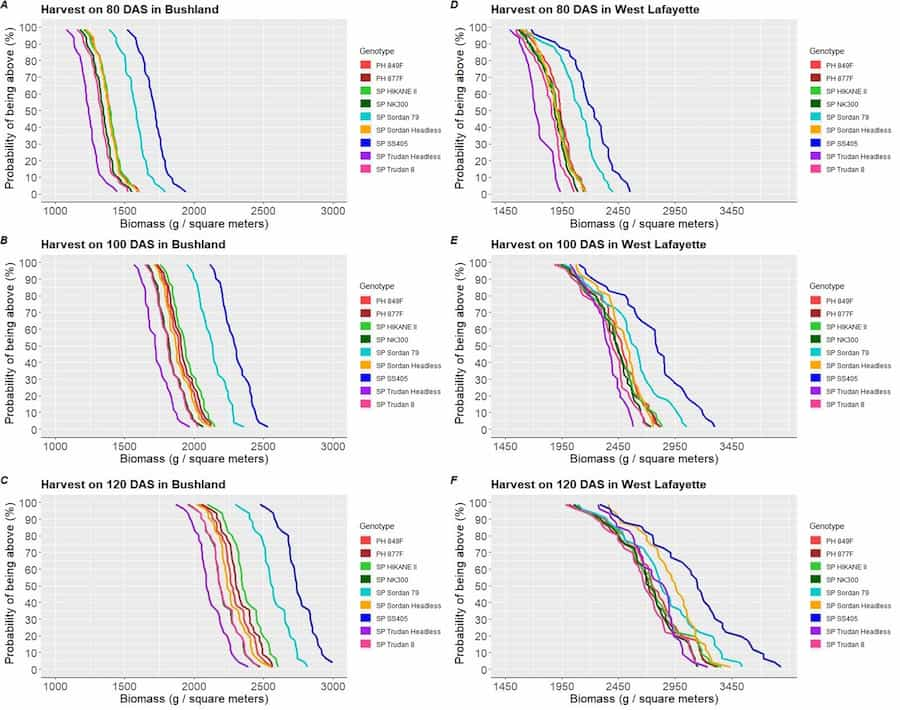
The authors used an existing systems model, CROPGRO, to predict phenological stages in new environments using a large intercontinental dataset recording the timing of soybean developmental stages. They found that the existing model failed to generalize well across all environments and maturities because it simply used a time-series of daily temperatures and photoperiod (e.g., degree days) to determine the calendar day of a developmental event. “While systems models work well under specific conditions, they are not sufficiently generalizable to support agronomic and breeding decisions across a variety of environmental conditions and continuous relative maturities” explains Dr. Ryan McCormick, lead author in the study.
The authors undertook several approaches to improve CROPGRO.
First, they used a highly parallelized multi-model optimization strategy to re-fit CROPGRO. Using an evolutionary algorithm, 36 parameters were explored to identify equifinality and similarly behaving families of parameters. The parameter vector with the optimum fit found at the end of any round of evolution was retained and used as the set of optimized parameters for subsequent analyses using CROPGRO. The refitted model (“CROPGRO optimized”) performed better after refitting process compared to the previous version.
Next, the authors developed machine-learned models using neural networks. Trained with inputs of minimum daily temperature, maximum daily temperature, solar radiation, photoperiod, and relative maturity, these models accurately predicted daily developmental stages. The inclusion of “CROPGRO optimized” predictions as features in the network model improved the accuracy in their predictions, indicating that machine learning can be improved by including expert-engineered features of knowledge-based models.
The collection of 20 knowledge-based and data-driven models were then combined to further improve prediction. The authors combined the models with each individual model’s prediction equally weighted in the final ensemble prediction. They also used super learning, which weighted the models according to their performance. The super learner out-performed the simple ensemble of models, but was similar to “CROPGRO optimized” (see figure).
Messina and McCormick agree that, “this work demonstrates that machine models are no substitute for models developed based on scientific knowledge but the fusion of both approaches, science-based models can solve at least in part the problem of model underdetermination of machine models, can lead to better predictions and to uncover new knowledge.
The Decision Support System for Agrotechnology Transfer (DSSAT) community is committed to promoting development of all DSSAT models and software tools as open source projects. The DSSAT Cropping System Model (CSM) code, including CROPGRO, is fully open and accessible at https://github.com/DSSAT/dssat-csm-os


